
«`html
Введение в SWE-Lancer: новый подход к оценке ИИ в программной инженерии
Адаптация к новым вызовам в программной инженерии начинается с реального понимания ее сложности. Традиционные методы оценки часто не учитывают реальную практику фриланса. Фрилансеры работают с полными кодовыми базами, интегрируют различные системы и управляют сложными требованиями клиентов. Методы, которые фокусируются на юнит-тестах, пропускают важные аспекты, такие как производительность полного стека и экономическое влияние решений. Необходимы более реалистичные методы оценки.
Что такое SWE-Lancer?
OpenAI представляет SWE-Lancer — новый стандарт для оценки производительности моделей в реальных условиях фриланса. Бенчмарк основан на более чем 1400 заданиях с Upwork и от других источников, с общим вознаграждением в 1 миллион долларов. Задачи варьируются от небольших исправлений до значительных внедрений функций.
Ключевые особенности SWE-Lancer
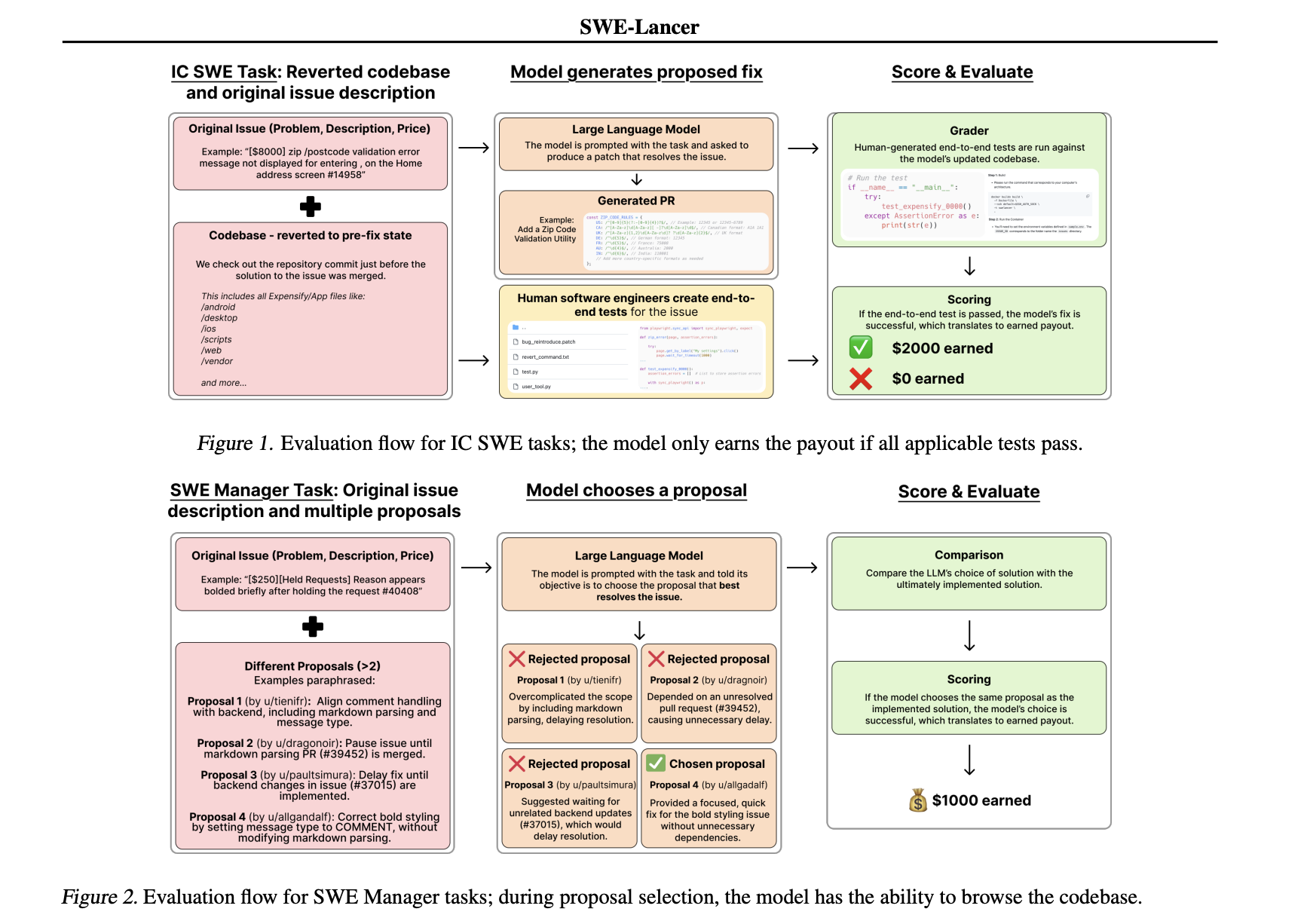
Одним из основных преимуществ SWE-Lancer является использование комплексных тестов вместо изолированных юнит-тестов. Эти тесты тщательно разработаны и проверены профессиональными разработчиками. Они моделируют весь процесс работы пользователя — от выявления проблем до проверки исправлений. Единый Docker-образ для оценки гарантирует, что каждая модель тестируется в одинаковых условиях.
Преимущества рукоприменения
Технические детали SWE-Lancer учитывают реальности фриланса. Задачи требуют изменений в нескольких файлах и интеграций с API, охватывая как мобильные, так и веб-платформы. Модели должны не только создавать код, но и выбирать лучшие предложения из нескольких вариантов. Это отражает настоящие обязанности инженеров-программистов.
Результаты SWE-Lancer
Результаты SWE-Lancer предоставляют ценные данные о текущих возможностях языковых моделей в программной инженерии. Модели GPT-4o и Claude 3.5 Sonnet показали результаты 8% и 26.2% соответственно. В управленческих задачах лучший результат составил 44.9%. Эти цифры показывают, что, хотя модели предлагают многообещающие решения, все еще существует значительный потенциал для улучшения.
Заключение
SWE-Lancer представляет собой обоснованный и реалистичный подход к оценке ИИ в программной инженерии. Этот бенчмарк связывает производительность модели с реальной денежной ценностью и подчеркивает задачи полного стека. Он способствует переходу от синтетических метрик оценки к методам, которые отражают экономические и технические реалии фриланса.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта, эффективно используйте SWE-Lancer.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации. Это поможет вашим клиентам извлечь выгоду из ИИ. Решите, какие ключевые показатели эффективности (KPI) вы хотите улучшить с помощью ИИ.
Подбирайте подходящее решение и внедряйте ИИ постепенно. Начните с небольшого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученного опыта.
Если вам нужны советы по внедрению ИИ, напишите нам в Telegram. Следите за новостями о ИИ в нашем канале или в Twitter.
Попробуйте AI Sales Bot — этот AI ассистент помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab — будущее уже здесь!
«`



















