
LightLLM: Решение для развертывания крупных языковых моделей в ограниченных средах
Практические решения и ценность
Большие языковые модели (LLM) значительно продвинулись за последние годы. Однако их применение в реальном мире ограничено из-за высоких требований к вычислительной мощности и памяти. Для улучшения доступности LLM на устройствах с ограниченными ресурсами разрабатываются более эффективные фреймворки для вывода и развертывания моделей. Существующие методы включают техники аппаратного ускорения и оптимизации, такие как квантизация и обрезка. Однако эти методы часто не обеспечивают баланс между размером модели, производительностью и удобством использования в ограниченных средах.
Исследователи разработали эффективный, масштабируемый и легковесный фреймворк для вывода LLM, LightLLM, чтобы решить проблему эффективного развертывания LLM в средах с ограниченными вычислительными ресурсами, таких как мобильные устройства, ресурсоемкие среды и краевые вычисления. Он направлен на снижение вычислительной нагрузки, сохраняя точность и удобство использования моделей. LightLLM использует комбинацию стратегий, включая квантизацию, обрезку и дистилляцию, для оптимизации LLM для ограниченных сред. Эти техники гарантируют уменьшение размера модели при сохранении ее производительности. Кроме того, фреймворк разработан с учетом удобства использования, что делает его доступным для разработчиков на разных уровнях экспертизы. LightLLM также интегрирует оптимизацию компилятора и аппаратное ускорение для дальнейшего улучшения производительности модели на различных устройствах, от мобильных до краевых вычислительных сред.
Основные техники оптимизации в LightLLM включают квантизацию, которая уменьшает точность весов модели, делая их более компактными и эффективными для обработки. Эта техника критически важна для снижения требований к памяти без значительной потери точности. Обрезка — еще один ключевой метод, при котором удаляются ненужные соединения в модели, дополнительно уменьшая вычислительную нагрузку. Дистилляция используется для передачи знаний большой, сложной модели на более маленькую, более эффективную версию, которая все равно хорошо справляется с задачами вывода.
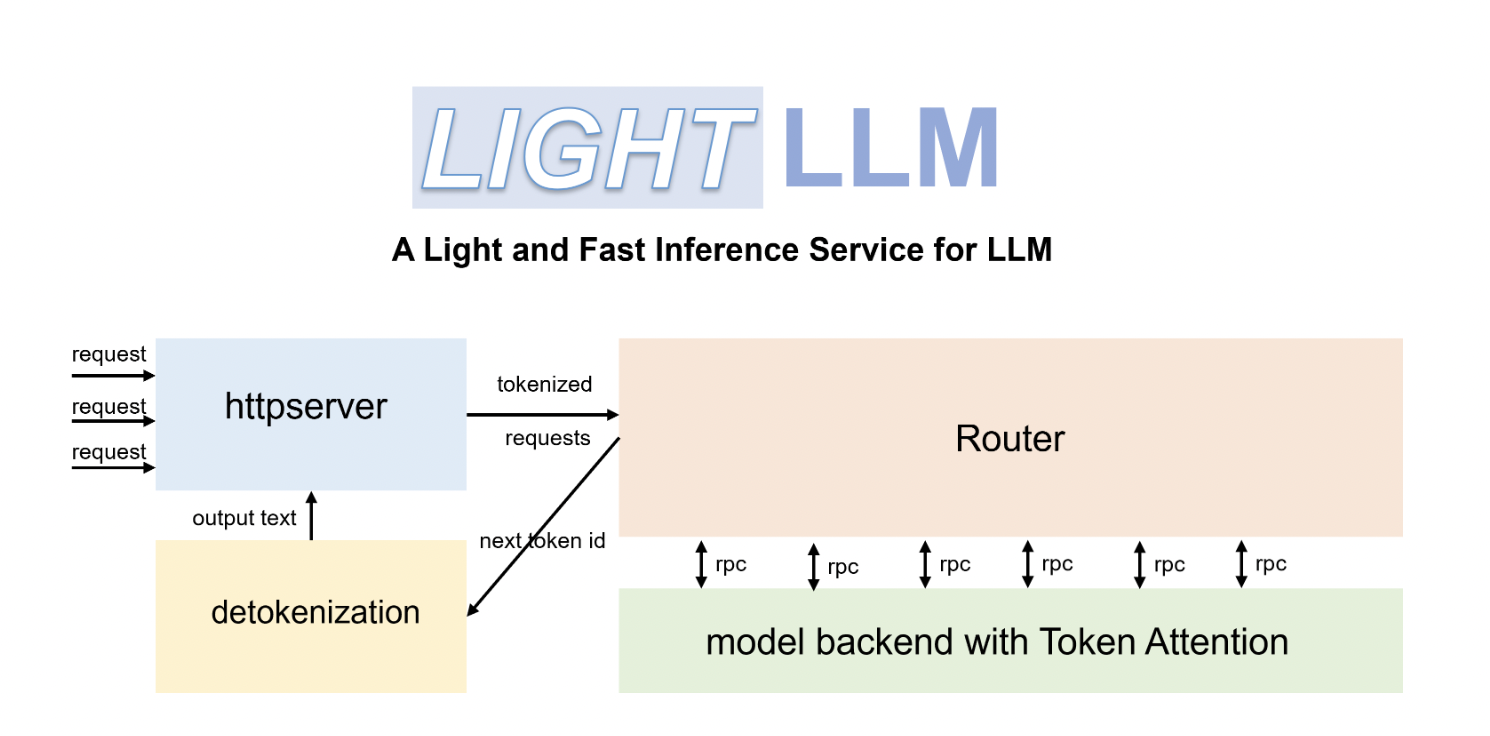
Архитектура LightLLM включает несколько компонентов, таких как загрузчик моделей для обработки и предварительной обработки LLM моделей, движок вывода для выполнения вычислений, модули оптимизации для применения квантизации и обрезки, а также интерфейс аппаратного обеспечения для полного использования возможностей устройства. Вместе эти компоненты обеспечивают высокую производительность LightLLM в терминах скорости вывода и использования ресурсов. Он продемонстрировал впечатляющие результаты, снижая размеры моделей и времена вывода, сохраняя точность оригинальных моделей.
В заключение, LightLLM представляет собой комплексное решение для проблемы развертывания крупных языковых моделей в ограниченных средах. Интегрируя различные методы оптимизации, такие как квантизация, обрезка и дистилляция, LightLLM предлагает эффективный и масштабируемый фреймворк для вывода LLM. Его легковесный дизайн и высокая производительность делают его ценным инструментом для разработчиков, желающих запускать LLM на устройствах с ограниченной вычислительной мощностью, расширяя возможности для приложений на базе ИИ.





















