
«`html
SepLLM: Практическое ИИ-решение для эффективного разреженного внимания в больших языковых моделях
Введение
Большие языковые модели (LLM) демонстрируют выдающиеся способности в обработке естественного языка, но их эффективность часто снижается из-за сложности механизма самовнимания. Это особенно заметно при работе с длинными последовательностями, где растут вычислительные и памятьные требования. Решения, которые изменяют самовнимание, могут не сочетаться с предобученными моделями, а оптимизация кэшей ключей-значений может привести к несоответствиям между обучением и выводом.
Что такое SepLLM?
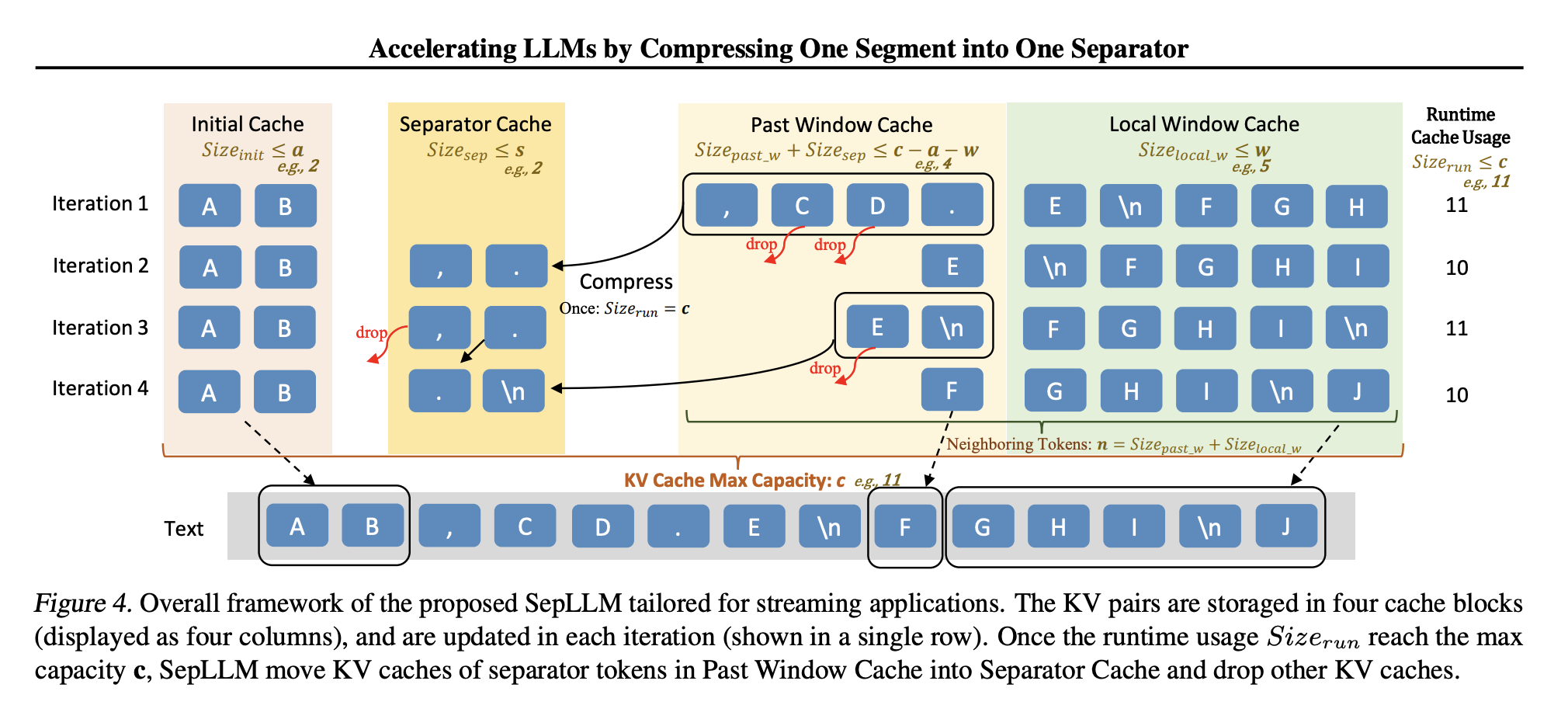
Исследователи из Huawei Noah’s Ark Lab и других организаций предложили SepLLM — механизм разреженного внимания, который упрощает вычисления внимания. SepLLM акцентирует внимание на трех типах токенов:
- Начальные токены: первые токены в последовательности, важные для понимания контекста.
- Соседние токены: токены, находящиеся рядом с текущим токеном, обеспечивающие локальную согласованность.
- Разделительные токены: часто встречающиеся токены, такие как запятые и точки, которые содержат информацию на уровне сегментов.
Преимущества SepLLM
- Разреженный механизм внимания: Сокращает количество вычислений, повышая эффективность без ущерба для производительности модели.
- Улучшенная обработка длинных текстов: SepLLM обрабатывает последовательности более четырех миллионов токенов, что особенно полезно для задач, таких как резюмирование документов.
- Увеличенная эффективность вывода и памяти: механика сжатия на основе разделительных токенов ускоряет вывод и снижает использование памяти. Например, на тестах было показано снижение использования кэша KV на 50%.
- Гибкость развертывания: SepLLM легко интегрируется с предобученными моделями и поддерживает обучение с нуля и донастройку.
Экспериментальные результаты
SepLLM продемонстрировала свою эффективность в различных сценариях:
- Безобучающая настройка: На тестах GSM8K-CoT SepLLM показала сопоставимую производительность с полным вниманием, при этом использование кэша KV снизилось до 47%.
- Обучение с нуля: При применении к модели Pythia-160M-deduped SepLLM достигла более быстрой сходимости и улучшенной точности задач.
- Постобучение: SepLLM адаптировалась к предобученным моделям через донастройку, обеспечивая устойчивое снижение потерь.
- Потоковые приложения: SepLLM успешно справилась с потоковыми сценариями, такими как многоповторные диалоги.
Заключение
SepLLM решает ключевые проблемы масштабируемости и эффективности LLM, сосредоточив внимание на начальных, соседних и разделительных токенах. С её помощью можно обрабатывать длинные контексты и снижать нагрузку на ресурсы.
Внедрите ИИ в свой бизнес
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, используйте SepLLM. Определите, как ИИ может изменить вашу работу и где возможна автоматизация. Начинайте с малого проекта и постепенно расширяйте внедрение ИИ.
Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
«`




















