
«`html
Искусственный интеллект: новые возможности для вашего бизнеса
Искусственный интеллект постоянно развивается, сосредотачиваясь на оптимизации алгоритмов для улучшения производительности и эффективности больших языковых моделей (LLM). Одной из ключевых областей в этой сфере является обучение с подкреплением на основе обратной связи от людей (RLHF), направленное на согласование моделей ИИ с человеческими ценностями и намерениями, чтобы обеспечить их полезность, честность и безопасность.
Оптимизация функций вознаграждения
Одним из основных вызовов в RLHF является оптимизация функций вознаграждения, используемых в обучении с подкреплением. Традиционные методы включают сложные многоэтапные процессы, требующие значительных вычислительных ресурсов и могут привести к субоптимальной производительности из-за расхождений между метриками обучения и вывода. Существующие исследования включают методы, такие как DPO, IPO, KTO и ORPO, которые предлагают вариации обработки предпочтительных данных и оптимизации без ссылочных моделей, стремясь упростить RLHF, решая сложности и неэффективности, присущие традиционным методам.
Преимущества SimPO
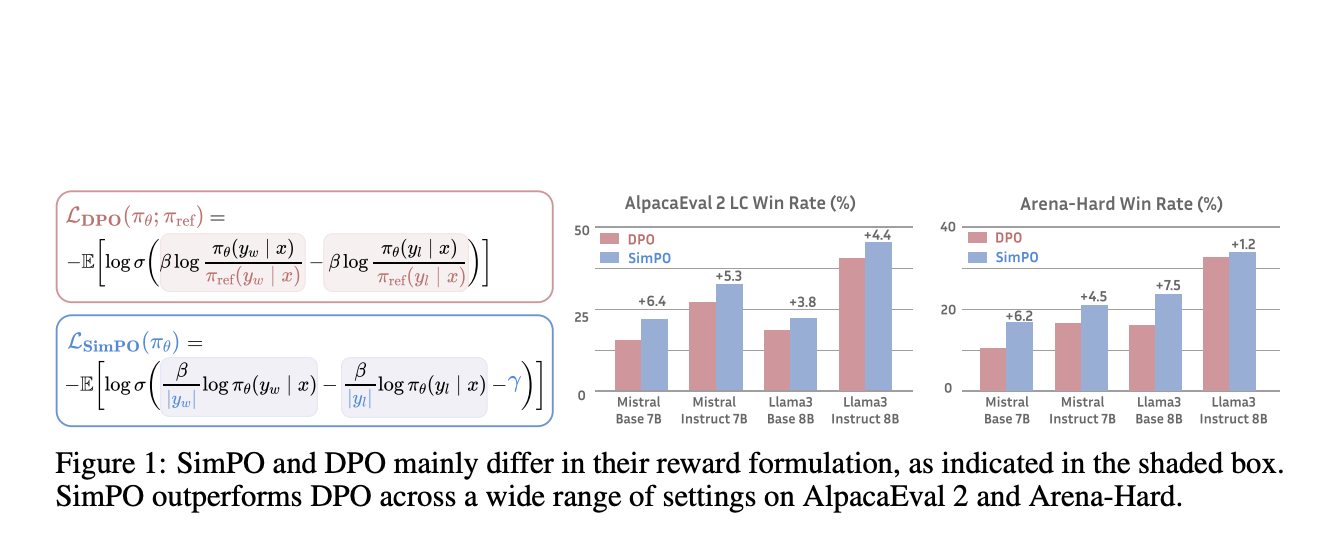
Исследователи из Университета Виргинии и Принстонского университета представили SimPO — более простой и эффективный подход к оптимизации предпочтений. SimPO использует среднюю логарифмическую вероятность последовательности в качестве неявного вознаграждения, лучше соответствуя генерации модели и устраняя необходимость в ссылочной модели. Кроме того, SimPO включает целевую границу вознаграждения для обеспечения значительной разницы между победными и проигрышными ответами, что улучшает стабильность производительности.
Практическая ценность SimPO
SimPO значительно превосходит DPO и его последние варианты на различных тренировочных установках, включая базовые и инструкционно настроенные модели. На бенчмарке AlpacaEval 2 SimPO превзошел DPO на 6,4 пункта, продемонстрировав значительное улучшение в генерации точных и актуальных ответов. Кроме того, SimPO показал еще более впечатляющую производительность на сложном бенчмарке Arena-Hard, превзойдя DPO на 7,5 пункта. Топовая модель, построенная на Llama3-8B-Instruct, достигла замечательной длинно-контролируемой победной доли в 44,7% на AlpacaEval 2 и 33,8% на Arena-Hard, что делает ее самой мощной 8B моделью с открытым исходным кодом на сегодняшний день.
Практическая применимость SimPO
SimPO использует данные предпочтений более эффективно, что приводит к более точному ранжированию вероятности победы и поражения на проверочном наборе данных. Это переводится в более эффективную модель политики, способную последовательно генерировать высококачественные ответы. Эффективность SimPO также проявляется в его вычислительных требованиях, снижая необходимость в обширных вычислительных ресурсах.
Заключение
SimPO представляет собой значительное достижение в оптимизации предпочтений для RLHF, предлагая более простой и эффективный метод, который последовательно обеспечивает превосходную производительность. За счет устранения необходимости в ссылочной модели и согласования функции вознаграждения с метрикой генерации, SimPO решает ключевые проблемы в этой области, предоставляя надежное решение для улучшения качества больших языковых моделей.
Подробнее ознакомьтесь с исследованием и GitHub.
Вся заслуга за это исследование принадлежит исследователям этого проекта.
Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу, Discord-каналу и LinkedIn-группе.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпишитесь на наш SubReddit. Также ознакомьтесь с нашей платформой AI Events Platform.