
«`html
Преимущества SwiftKV в области ИИ
Большие языковые модели (LLMs) играют важную роль в искусственном интеллекте, но их широкое применение сталкивается с трудностями, такими как высокие вычислительные затраты и задержки. Для решения этих проблем команда Snowflake AI Research разработала SwiftKV.
Что такое SwiftKV?
SwiftKV — это решение, которое улучшает производительность LLM и снижает затраты на инференс. Оно использует технологии кэширования, чтобы повторно использовать промежуточные вычисления и избегать лишних расчетов.
Преимущества SwiftKV
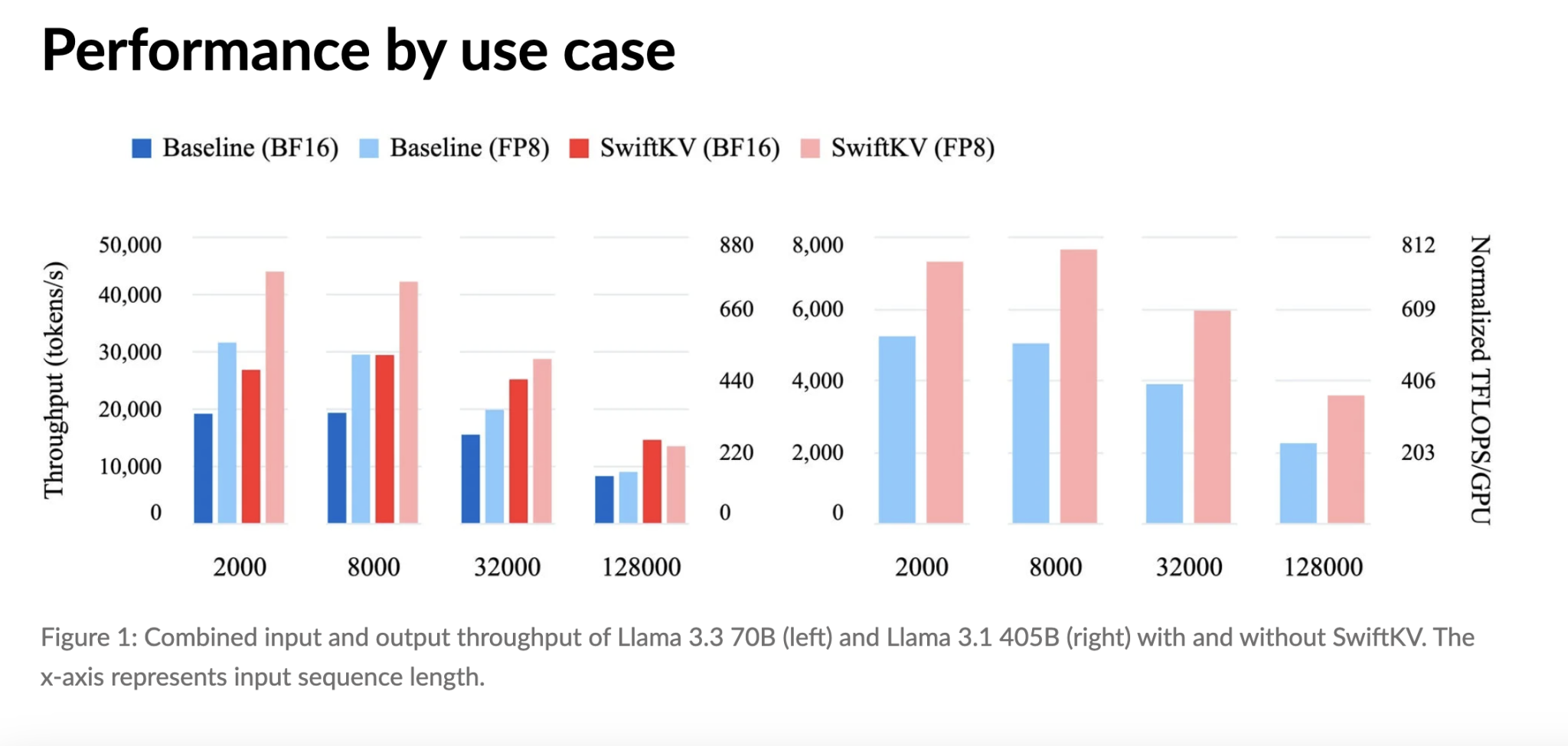
- Снижение затрат: Уменьшение избыточных вычислений может сократить затраты на инференс до 75%.
- Увеличение пропускной способности: Кэширование ускоряет время отклика.
- Экономия энергии: Меньшие вычислительные требования приводят к снижению потребления энергии.
- Масштабируемость: SwiftKV подходит для крупных развертываний.
Технические детали SwiftKV
- Кэширование ключ-значение: Во время инференса SwiftKV захватывает промежуточные активации и их результаты, что позволяет избегать повторных вычислений для схожих запросов.
- Эффективное управление памятью: Используется механизм LRU для оптимизации хранения кэша.
- Легкая интеграция: SwiftKV совместим с существующими фреймворками, такими как Hugging Face и Meta LLaMA.
Результаты применения SwiftKV
Использование SwiftKV с моделями Meta LLaMA показало снижение затрат на инференс до 75% без потери точности. Также отмечено сокращение времени задержки, что делает его привлекательным выбором для организаций, стремящихся оптимизировать свои решения в области ИИ.
Заключение
SwiftKV предлагает практическое решение для вызовов, связанных с развертыванием LLM. Оно помогает снизить затраты и задержки, делая ИИ более доступным. Открытый исходный код SwiftKV способствует сотрудничеству в сообществе ИИ, позволяя разработчикам и исследователям улучшать технологии.
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, грамотно используйте решения, такие как SwiftKV. Проанализируйте, как ИИ может изменить вашу работу и определите ключевые показатели эффективности (KPI), которые хотите улучшить.
Если вам нужны советы по внедрению ИИ, пишите нам в наш Telegram канал или следите за новостями в Twitter.
«`




















