
«`html
Визатроник: Прорыв в синтезе речи с использованием мультимодальных технологий
Синтез речи стал важной областью исследований, направленной на создание естественного и синхронизированного звука из различных источников. Объединение текстовых, видео и аудио данных позволяет более точно имитировать человеческое общение.
Проблемы и решения
Сложность заключается в точном согласовании речи с визуальными и текстовыми подсказками. Традиционные методы, такие как генерация речи на основе движения губ, имеют свои ограничения. Они часто не могут поддерживать синхронизацию и естественность в многоязычных или сложных визуальных контекстах.
Существующие инструменты сильно зависят от однотипных входных данных или сложных архитектур для мультимодальной интеграции. Например, модели обнаружения губ используют предобученные системы, а текстовые системы обрабатывают только лексические особенности. Однако их производительность остается низкой, так как они не учитывают более широкие визуальные и текстовые динамики.
Модель Visatronic
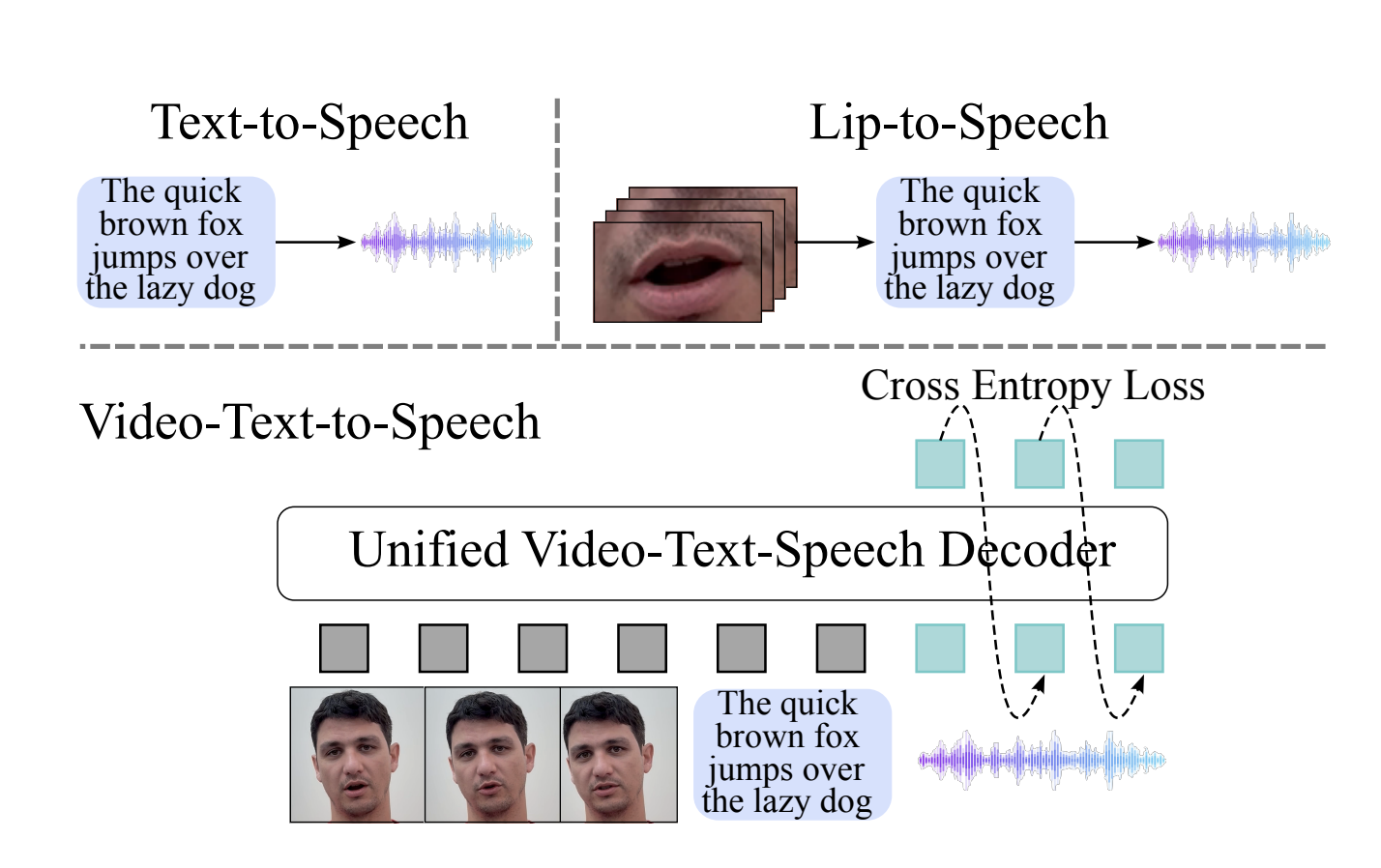
Исследователи из Apple и Университета Гуэлфа разработали новую мультимодальную модель под названием Visatronic. Эта модель обрабатывает видео, текст и речь через общую пространство встраивания, что позволяет генерировать речь, синхронизированную с текстовыми и визуальными входами.
Visatronic использует векторно-квантованный вариационный автокодер для кодирования видео в дискретные токены и упрощенный подход для представления речи. Текстовые данные обрабатываются на уровне символов, что улучшает обобщение. Все эти данные интегрируются в единую архитектуру трансформера, что позволяет взаимодействовать между входами.
Преимущества Visatronic
Visatronic продемонстрировала значительные улучшения в производительности на сложных наборах данных. Например, на наборе VoxCeleb2 модель достигла уровня ошибки слов 12.2%, что лучше, чем у предыдущих подходов. Также она показала 4.5% на наборе LRS3 без дополнительного обучения.
Интеграция видео не только улучшила генерацию контента, но и сократила время обучения. Модели Visatronic достигли сравнимых результатов после двух миллионов шагов обучения, в то время как текстовые модели требовали три миллиона.
Заключение
Visatronic представляет собой прорыв в мультимодальном синтезе речи, решая ключевые проблемы естественности и синхронизации. Эта инновация открывает новые возможности для применения в области дубляжа видео и технологий доступной коммуникации.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), используйте Visatronic. Проанализируйте, как ИИ может изменить вашу работу, определите ключевые показатели эффективности (KPI) и подберите подходящее решение.
Внедряйте ИИ постепенно: начните с малого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot — этот AI ассистент в продажах помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`




















