
Введение в многомодальное рассуждение
Модели визуального языка (VLM) продемонстрировали значительные успехи в задачах, связанных с восприятием, таких как визуальное ответ на вопросы (VQA) и визуальное рассуждение на основе документов. Однако их эффективность в задачах, требующих сложного рассуждения, остается ограниченной из-за нехватки качественных и разнообразных обучающих наборов данных.
Проблемы существующих наборов данных
Существующие мультимодальные наборы данных имеют несколько недостатков: некоторые из них узко сфокусированы на конкретных научных изображениях, другие полагаются на синтетические данные, которые не обеспечивают обобщение в реальном мире, а многие слишком малы или упрощены для разработки надежных способностей к рассуждению. Из-за этих ограничений VLM с трудом справляются с многопроцессными задачами.
Автоматизация сбора данных
Поскольку ручная аннотация в больших объемах затруднена, исследователи изучили автоматизированные подходы к сбору данных. Метод WebInstruct, позволяющий извлекать текст, ориентированный на рассуждения, из интернета, стал основой для расширения подхода к мультимодальному рассуждению. Однако отсутствие масштабных мультимодальных наборов данных и ограничения текущих моделей извлечения данных препятствуют его реализации.
Стратегии улучшения мультимодального рассуждения
Исследователи изучили различные стратегии, такие как нейросимволическое рассуждение, оптимизированное визуальное кодирование и структурированные рамки рассуждения. Хотя такие модели, как GPT-4o и Gemini, демонстрируют выдающиеся результаты, их ограниченный доступ способствовал разработке открытых альтернатив, таких как LLaVA и MiniGPT-4.
Внедрение VisualWebInstruct
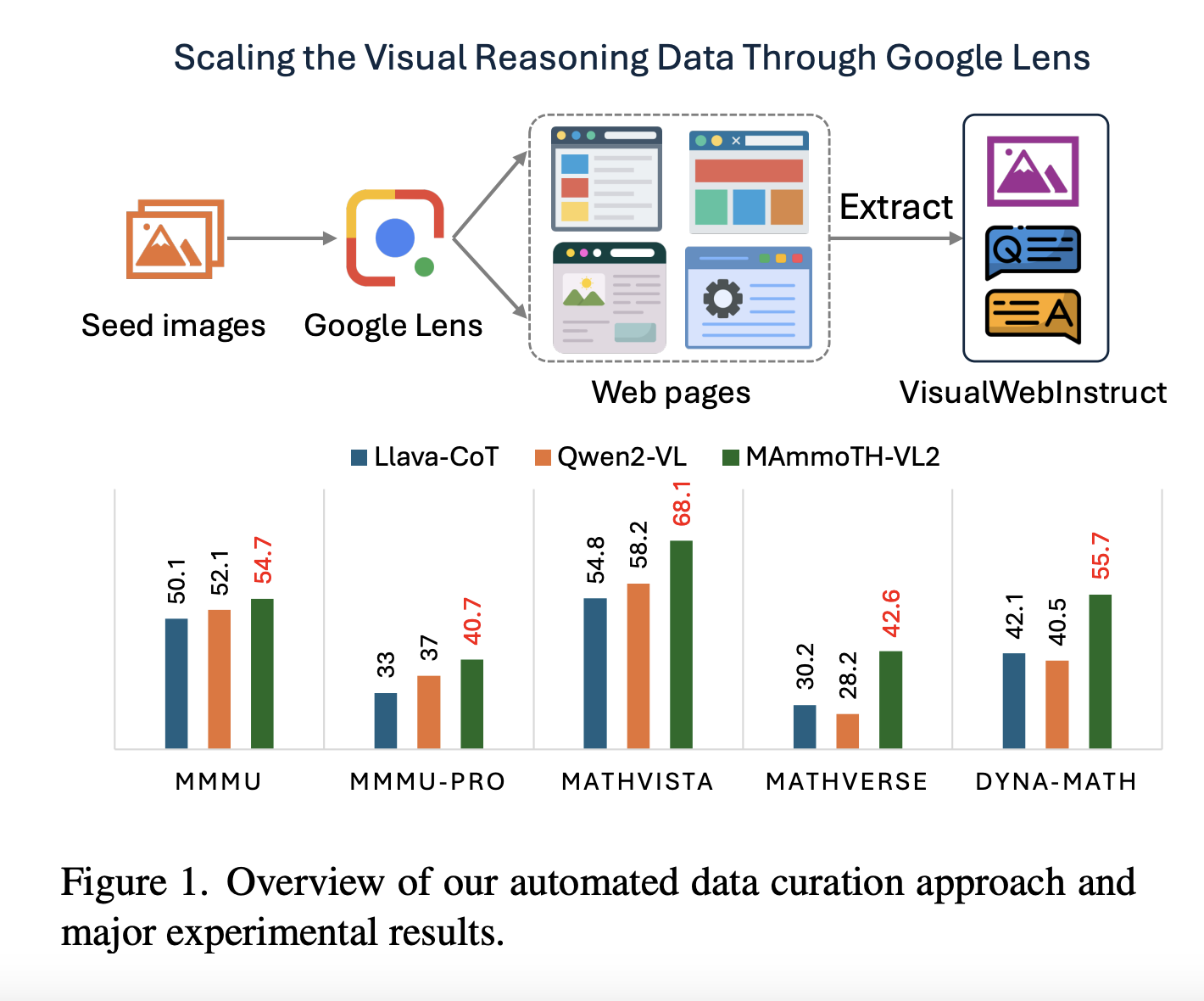
Исследователи из различных университетов представили набор данных VisualWebInstruct, чтобы улучшить VLM. С помощью Google Image Search был собран большой объем изображений, что привело к созданию более 1 миллиона пар вопрос-ответ. Этот набор данных значительно улучшил сложные задачи рассуждения для VLM, что подтверждается высокими результатами на нескольких тестах.
Заключение и рекомендации
В заключение, исследование предлагает способы создания масштабируемых наборов данных для мультимодального рассуждения без человеческой аннотации. Используйте методы, аналогичные VisualWebInstruct, для автоматизации процессов в вашем бизнесе. Идентифицируйте ключевые моменты, где искусственный интеллект может добавить максимальную ценность, и начните с небольших проектов, постепенно расширяя применение ИИ.
Контактная информация
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Подписывайтесь на наши обновления в Telegram здесь.




















