

 за 6 месяцев.
А что бы вы сделали с этими деньгами?
за 6 месяцев.
А что бы вы сделали с этими деньгами? за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?
за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?  . Как это работает?
. Как это работает?  . Расскажите подробнее!
. Расскажите подробнее! 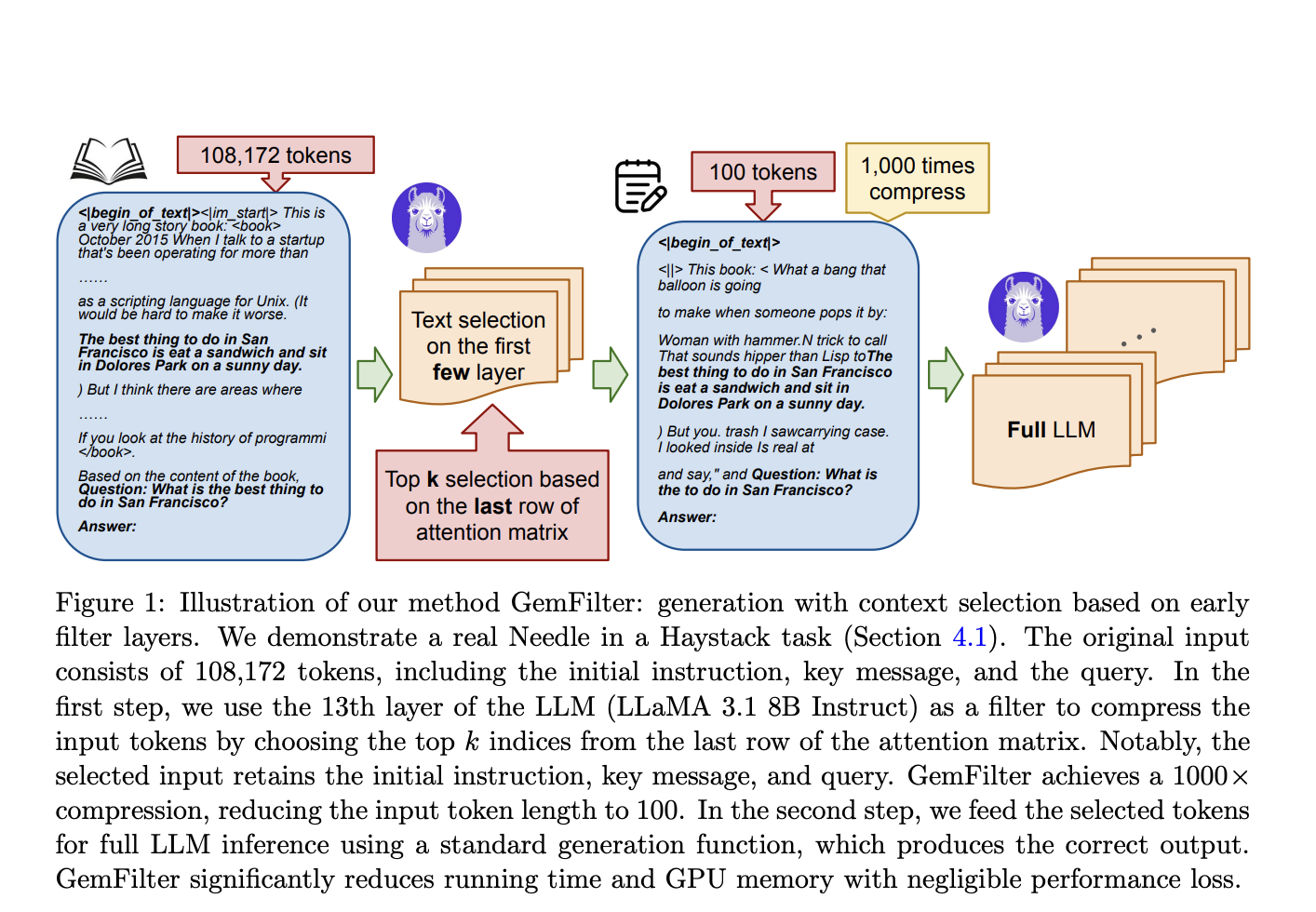
Применение GemFilter для ускорения вывода LLM и снижения потребления памяти
Оптимизация работы с длинными входными последовательностями
Большие языковые модели (LLM) сегодня являются неотъемлемой частью многих систем искусственного интеллекта, обладая выдающимися возможностями в различных приложениях. Однако с увеличением требования к обработке вводов с длинным контекстом исследователи сталкиваются с значительными препятствиями в оптимизации производительности LLM. Эффективная работа с обширными входными последовательностями критична для расширения функциональности ИИ агентов и улучшения техник аугментации генерации информации.
Недавние достижения позволили увеличить возможности LLM для обработки вводов до 1 миллиона токенов, однако это требует значительных затрат вычислительных ресурсов и времени. Основные проблемы заключаются в ускорении скорости генерации LLM и снижении использования памяти GPU для входов с длинным контекстом, что необходимо для минимизации задержки ответа и увеличения пропускной способности в вызовах API LLM.
Одним из решений является подход GemFilter, разработанный исследователями из университетов University of Wisconsin-Madison, Salesforce AI Research и The University of Hong Kong. Этот метод позволяет значительно сжимать длинные входные последовательности, анализируя матрицу внимания с ранних слоев LLM для отбора необходимой информации. Применение подхода GemFilter позволяет добиться значительного ускорения и сокращения использования памяти GPU во время фазы вычисления запроса, сохраняя при этом производительность сопоставимую с существующими методами в фазе итеративной генерации.
Эксперименты показывают, что подход GemFilter обеспечивает значительные улучшения в эффективности вычислений и использовании ресурсов, что делает его мощным инструментом для оптимизации работы LLM в задачах с длинным контекстом.




































