
Эффективное вычисление скрытых представлений запросов и элементов для приближения оценок CE
Кросс-энкодеры (CE) оценивают сходство, кодируя одновременно пару запрос-элемент, превосходя dot-product с моделями на основе встраивания при оценке релевантности запроса-элемента. Текущие методы выполняют поиск k-NN с CE, приближая CE-сходство пространством векторных встраиваний, соответствующим двойным энкодерам (DE) или факторизацией матрицы CUR. Однако методы на основе DE сталкиваются с проблемами низкой полноты из-за плохой обобщенности новых доменов и отделения тестового времени извлечения с DE от CE. Таким образом, методы на основе DE и CUR недостаточны для определенной конфигурации приложения в поиске k-NN.
Разреженная факторизация матриц
Разреженная факторизация матриц широко используется для оценки низкорангового приближения плотных расстояний и матриц, не являющихся положительно определенными, а также для заполнения пропущенных записей в разреженных матрицах.
Новый метод на основе разреженной факторизации матриц
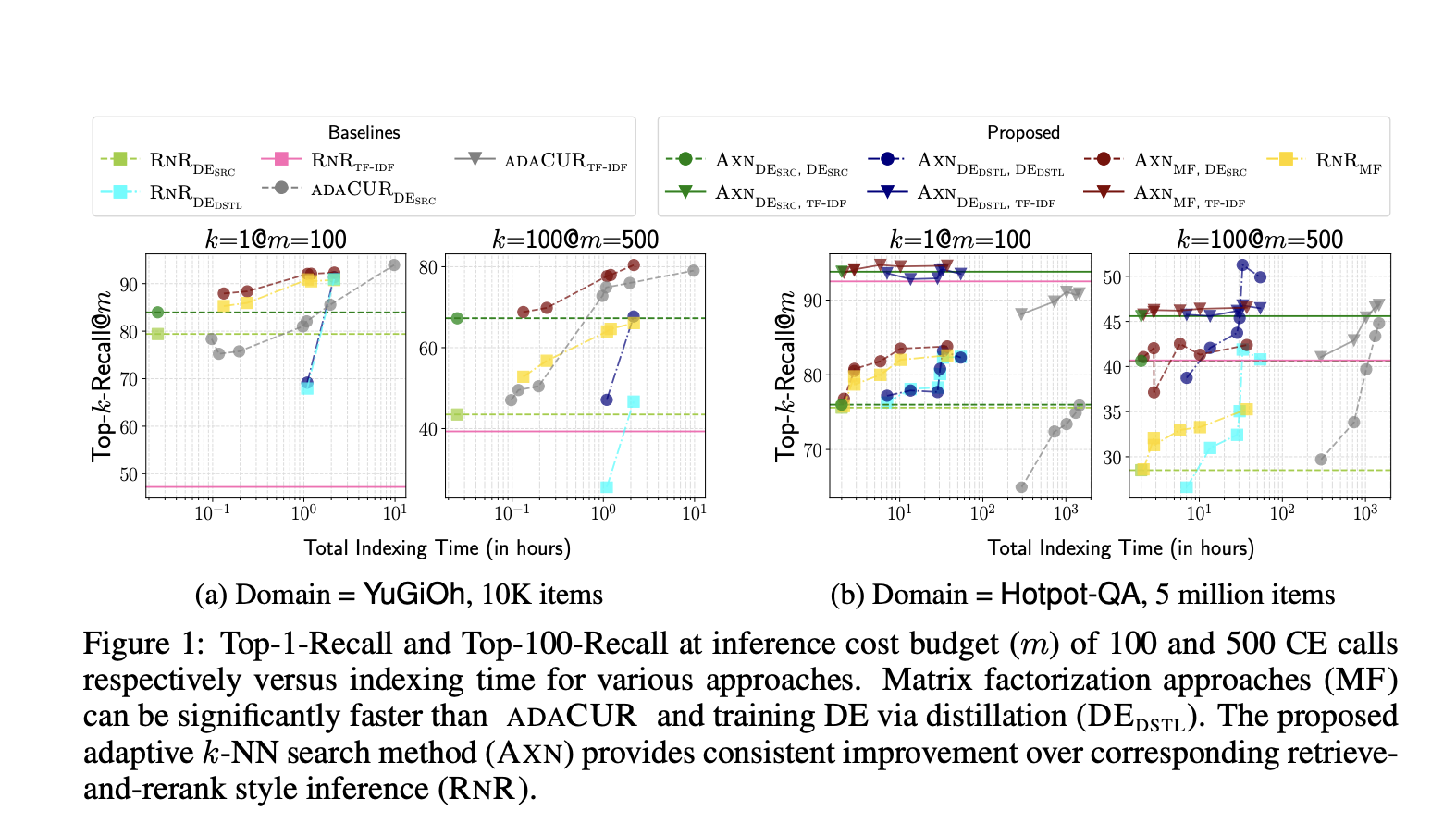
Исследователи из Университета Массачусетса в Амхерсте и Google DeepMind представили новый метод на основе разреженной факторизации матриц. Этот метод оптимально вычисляет скрытые представления запросов и элементов для приближения CE-оценок и выполняет поиск kNN, используя приближенное CE-сходство. В сравнении с методами на основе CUR, предложенный метод генерирует качественное приближение, используя лишь часть вызовов CE-сходства.
Эксперименты и оценка
Методы и базовые значения тщательно оцениваются на задачах, таких как поиск k-ближайших соседей для моделей CE и связанных задачах. Важно отметить, что модели CE используются для задач, таких как связывание сущностей без обучения и информационный поиск без обучения, демонстрируя, как различные решения влияют на время индексации данных и точность извлечения во время тестирования.
Заключение
Исследователи из Университета Массачусетса в Амхерсте и Google DeepMind представили метод на основе разреженной факторизации матриц, который эффективно вычисляет скрытые представления запросов и элементов. Этот метод оптимально выполняет поиск k-NN с кросс-энкодерами, эффективно приближая оценки кросс-энкодера с помощью скалярного произведения изученных тестовых встраиваний запроса и элемента.
Подробнее см. статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему подпишитесь на наш SubReddit.
Автор: MarkTechPost